Installation
First, install enochian.ProgramState using the OpenAIBackend.
Prompt Studio
You can optionally run it with Enochian Studio as well, a web view for the prompts being sent in. First, start the server.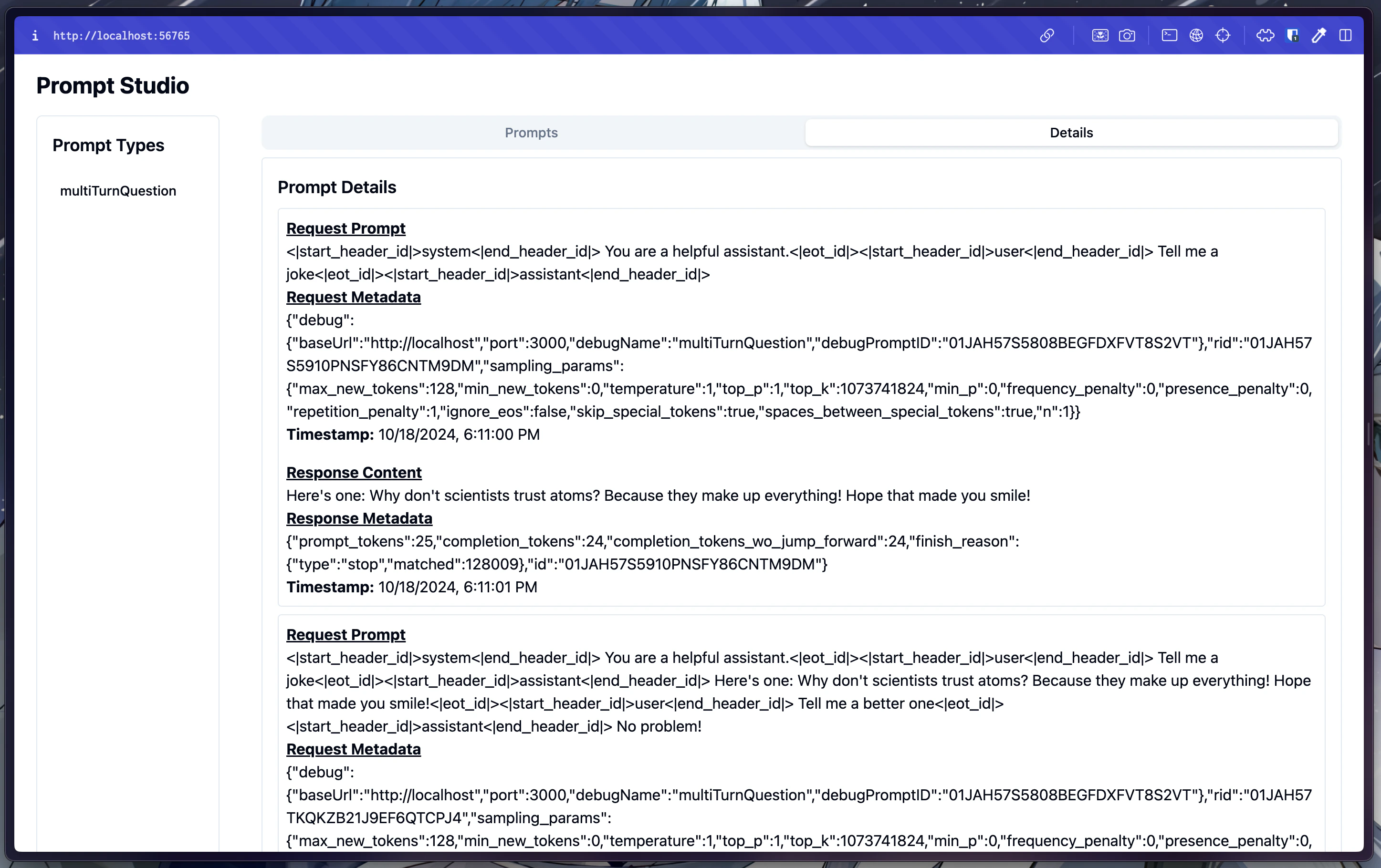
Get started in a few commands
ProgramState using the OpenAIBackend.